【采集学习】不用写代码的爬虫课637MB

【采集学习】不用写代码的爬虫课637MB
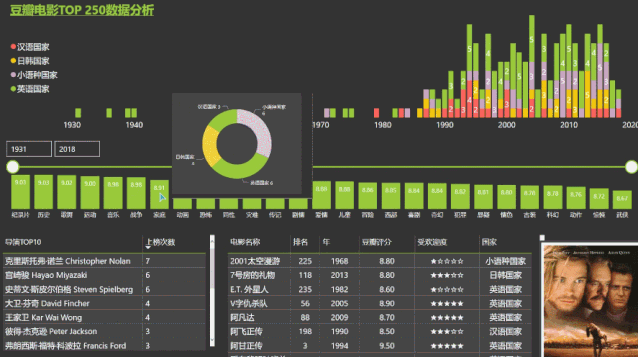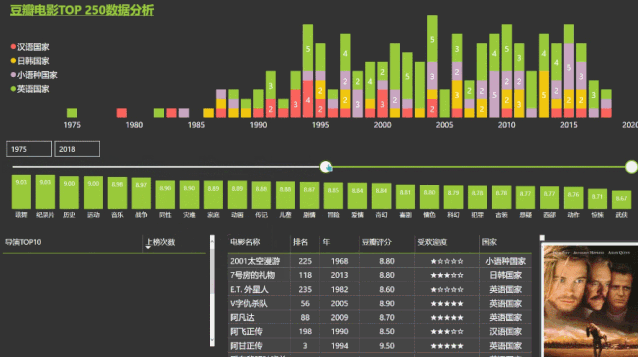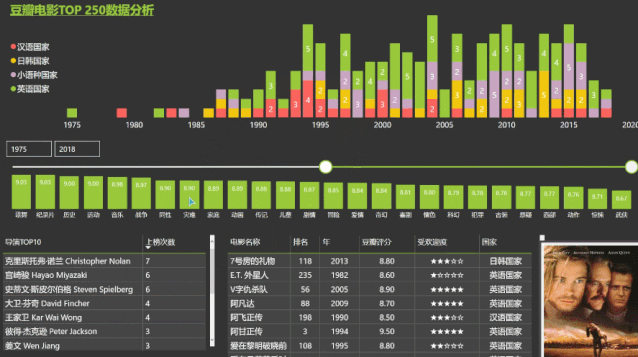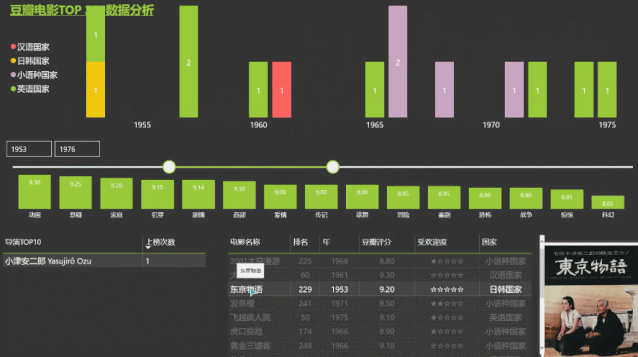
付费课程《不用写代码的爬虫课》小白快速学会采集
做网站很多地方都需要采集
一般采集有火车头,八爪鱼 用起来也麻烦
这个用审查元素就你学会采集,有兴趣的可以看看...


01. scrapy是什么
02. 初步使用scrapy
03. scrapy的基本使用步骤
04. 基本概念介绍1-scrapy命令行工具
05. 基本概念介绍2-scrapy的重要组件
06. 基本概念介绍3-scrapy中的重要对象
07. scrapy内置服务介绍
08. 抓取进阶-对“西刺”网站的抓取
09. “西刺”网站爬虫的核心代码解读
10. Scrapy框架解读—深入理解爬虫原理
11. 实用技巧1—多级页面的抓取技巧
12. 实用技巧2—图片的抓取
13. 抓取过程中的常见问题1—代理ip的使用
14. 抓取过程中的常见问题2—cookie的处理
15. 抓取过程中的常见问题3—js的处理技巧
16. scrapy的部署工具介绍-scrapyd
17. 部署scrapy到scrapyd
18. 课程总结